Yoasi, a Generative LLM Based Universe Builder

Introduction
I have always been drawn to the idea of building fantastic worlds with fractal complexity; the more you look, the more you see. Witnessing the advancement of LLM capabilities and reading papers like "Simulacra of Human Behavior"[1] truly piqued my interest in exploring the idea of creating generative worlds.
After a few weeks of work, Morgan Rivers and I, Mariana Meireles, developed Yoasi, a Generative LLM-Based Universe Builder. Yoasi draws on ideas from agent-based modeling, generative AI, the philosophical branch of practical reasoning, game theory, and my passion for storytelling. Currently, it allows developers to input Python files containing descriptions of agents and environments. Users can then initiate their simulations and read the logs produced by the software to delve into the lives of the agents within this universe.
Storytelling capabilities
Here, I'm going to discuss the functionalities of the simulation from a high-level perspective and will omit many of the technical details. If you're interested in a more technical approach, head over to the "Implementation details" section.
The simulation is simply divided in three periods: morning, afternoon and night. Each period is divided into turns, and each turn has different sub-turns that always occur in the same order: planning, traveling, conversing, acting. By the end of the day agents reflect on their day. Furthermore, the simulation needs several creative inputs to run. The inputs are responsible for both to describe the universe and the agents that habit it. Let’s start by taking a look into agent’s inputs and then move into the environment’s inputs.
Agent’s inputs
Name: The agent's name by which other agents will recognize them; currently, names must be unique.
Traits: Characteristics that can include anything: physical attributes, emotional responses, etc. You can be very specific or very broad. It's advisable not to write more than 200 words.
Age: The agent's age, which is an optional trait.
Location: The agent's current location; it will default to "home" for the first iteration of the simulation.
Home: The place where agents go to rest. By default, they will be directed there at the conclusion of every night period.
Status: This denotes a long-term plan or goal that your agent seeks to achieve. Think about aspirations like becoming the president of the local farmers' association or winning someone's heart. This variable should not be mistaken for the “Plan” variable, which will be detailed later on the post. Direct planning by agents cannot be influenced by the user; these are emergent strategies resulting from their interaction with the simulation
Environment’s inputs
Universe description: The universe itself requires a description. What are the social rules that govern this simulation? What significant environmental facts impact agents' lives, and of which should they be aware? These are the kinds of questions you should try to answer here. Again, it's advisable to keep it under 200 words.
Space description: This should not be confused with the "Universe description" variable. Spaces are the actual locations where agents will interact. Space descriptions should offer a high-level view and ideally be kept under 200 words. Within the space object, the information about other agents currently in that space is provided to the agents.
Space name: The name of a space; note that it should also be unique. For example: If you have two laboratories in your simulation, consider adding adjectives or nouns to make it more distinct and descriptive.
Now that we know what are the parts expected from us let’s dive in a bit deeper into the internals of this simulation to get an idea on what kinds of activities our agents will experience.
Turns
I’ve talked earlier about the different turns within an agent’s day. Each sub-turn happens concomitantly for all agents. This means all agents plan, travel, converse, etc., at the same time. Let’s go through each one of sub-turns in more detail:
Planning: At the start of each turn, an agent will recall the last few events they experienced. They'll observe their environment and, based on their traits and overarching goals, determine their actions for that time of day. This planning doesn’t require any additional inputs; it's akin to mentally preparing for one's day.
Traveling: Agents can decide where to go. They will receive a list of all the available places you’ve previously added and based on the plan they’ve just came up with they will try to decide which place is better to put their plans in action. Once they’ve decide they will be moved to that space.
Conversing: At this point agents have a plan and they’re in a new space (or the same space if they’ve decided not to travel). They can look around and decide to have a chat with other agent’s around them. The most pungent factor here is their traits and their plan. If an agent is overall shy and doesn’t like to engage with people, odds are they will start very few conversations. If their plan is something that demands extreme concentration or solitude they’ll also hardly ever start a conversation at this point and might cut off other agents that try to talk to them. At this point, the software only support conversations between two agents at a time. The agents remember the conversations in different ways, as they save it in the memories based on their own perspectives. You can have access to full conversations looking at the log.
Acting: Actions take place in the end of a turn, here agents will recollect their plan and try to execute it. Their environment, as well as previous interactions, can affect their actions. Often times conversations will also change their actions, sometimes allowing agents to collaborate together in a project. Actions are nudged towards having a sense of progression and agents usually go through a full arch pursuing whatever is their passion before they change to something else. Reflection: This phase only happens once a day due to its resource-intensive nature. Here agents will recollect the most important events of their day and try to make sense of it with a small summary. This phase is important to keep a consistent arch and give them a sense of progression. It might also be the most succinct relevant part for you to read once looking at the logs.
An user can run a simulation for as long as they want. The results are organized in a tree-structured directory, categorized by "day," "period," and "agent_name" for each respective element. Through this structure, users can access detailed outputs for each agent during every sub-turn, granting a comprehensive view of the simulation's events. The narrative quality relies heavily on the user's initial inputs and the specific LLM employed. For optimal story generation, users should ideally utilize a refined LLM tailored to their universe and invest time in crafting detailed descriptions for their agents and spaces.
Implementation details
For our agent’s internal response system we used a simple implementation of an agent with state described in the Multiagent Systems by Weiss[2]. Here, the agent, starting with an initial state I = i0, receives information S from their environment and generates a percept P, depicted as S → P. The state I is updated through the next function I * P or next(i0, see(S)), producing an action.

The state function shown in this diagram was implemented using three different memory retrieval methods: vector similarity[3], focused search, and highly contextual remembrance, that are used in different contexts depending on which sub-turn the agent is currently processing, and a ponderation step using highly contextual reflection.
Vector similarity’s ability to search extensively through large stretches of data was useful in the reflection and conversation phase. Because vector similarity is so resource intensive we opted to minimize its use and adopting slightly different approaches for each one of these phases. With the reflection phase being very thorough and taking about half of the time of a whole day’s simulation time to complete.
Focused search receives strings with specific keywords, or sentences to retrieve documents from the agent’s memory that are related to the search. This kind of memory retrieval method proved itself useful in the “acting” phase, in which agents had to remember specific actions they did in the past in order to build a consistent and progressive arch through their actions.
The highly contextual search provides agents the ability to input factors such as environmental description, the presence of other agents, and their ongoing plans and characteristics. This helps to gauge the ambient surroundings and facilitate highly contextual decisions. Being computationally economical, since it avoids in-depth memory scans, it's extensively used in the simulation and finds application in the planning, conversing, and acting phases.
Finally, for the ponderation step we’ve used highly contextual reflection. Similar to the highly contextual search, this reflection function is low on computational demand and is invoked during every sub-turn (except the reflection sub-turn, which utilizes deep vector similarity).
Further development
There are several different approaches that will greatly improve the quality of the story being generated by these agents. Here are a few fronts we’re considering tackling:
Meta-programming: One major constraint of the software is the agents' inability to influence and alter their surroundings. Often times agents will go in their own exciting pursuits and discover hidden caves, or new technologies. However, these discoveries remain confined to their memories, accessible to other agents only through conversations. With meta-programming their ideas and actions could come to reality fostering a richer lore that could be enjoyed by all other agents. Agents should also be allowed to lose or gain traits and change their long term goals. But to achieve all of this we need to introduce meta-programming elements to the code.
Improved belief system: Drawing from Weiss’ works I’d like to develop a new belief system, that’s illustrated in the following diagram:

A belief revision function takes in perceptual input and the agent’s current beliefs (which need to be set as a new variable with its own set of functions and logic). This function then generates several belief options for the agent. The subsequent three steps act like filters, fine-tuning these beliefs to the agent's traits and current state. Through the "desires" lens, we aim for the agent to select options that align more closely with their plans and goals. The "filters" phase eliminates options not fitting within the boundaries of the agent's personality. In the "intentions" step, we ensure that only options consistent with the agent’s current plans and goals are chosen. After this process, we should derive a more precise and realistic action. Another enhancement I'd like to introduce is modeling beliefs as a graph and weighting its edges. While some beliefs might fade, stronger ones should persist. This integrates well with the idea of giving agents a brain (it will be covered shortly). As this process is very computational intensive we’d probably only use it as a new way of generating actions for agents.
The reason for building such an involved system is because latest research seems to point out that having a good theory of mind is extremely important to LLM’s quality of outputs [8], [9].
Coordination games:
I’m deeply interested in solving coordination issues and for that game theory offers overarching algorithms. Empowering agents to interact with each other in well established and well modeled scenarios might allow for much more complex arcs to emerge in the world [10].
Below is a diagram showcasing various frameworks we could employ to facilitate better agent coordination:
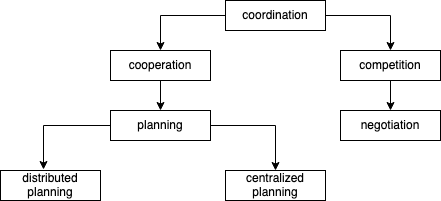
At the moment, I'm particularly intrigued by the use of different cooperation mechanisms, Baumman’s research is as an example[4]. I’m also curious about the coordination approaches offered by VCG auctions[5]. As an initial attempt to incorporate these games into a generative context, I'd like to start by experiment with auctions. Under a perspective of auctions we can model agent’s interactions under a managers and contractors perspective. Where the manager offers a task and judges the quality of the bids and the contractor should decline or try to bid in the auction. Here’s a break down of some of their responsibilities:
Manager’s perspective:
Announce a task that needs to be performed
Receive and evaluate bids from potential contractors
Award a contract to a suitable contractor
Receive and synthesize results
Contractor’s perspective:
Receive task announcements
Evaluate my capability to respond
Respond (decline or bid)
Perform the task (if agent’s bid was accepted)
Report my results
The very exciting thing about this idea is that there are several different games to explore with slight different modifications to the agents and the environment that could change the outcome of an interaction completely. The promises for emergent behavior out of these models are great.
Evolutionary brains:
Taking as an inspiration David Miller’s work on biosim4[6]. I would like to add the capability for agents to learn. Currently, this exploration is still in the very beginning. I would love to use something as elegant as neural circuit policies[7] for this project, however the nature of ODEs make it hard to adapt them into this project. I’m currently considering other kinds of reinforcement learning techniques and classic machine learning techniques. I believe adding brains to agents in conjunction with deeper methods of thought like the belief revision function will cause them to be much more consistent and acquire a stronger personality of their own.
Relationships:
I believe the lack of a relationship tracker greatly impoverish the interactions have with each other. Having a highly contextual memory for their relationship status with other agents, remembering specific things about other agents, what they like and dislike and acting based on the agent’s personality to tease or please other agents should improve this scenario.
How can I use this software?
We’ve decided to not open source this code because of the uncertainty around the advances of machine learning. Even though we don’t believe our code will necessarily be used to advance the AGI or bring the completion of existential risk scenarios we believe it’s possible, with enough computation, to achieve better results for specific requests with our code than with the current softwares available to the public.
However, this a project for art and for creating beautiful things and we’d still like it to be enjoyed by motivated creators. We’ve announced this project earlier this year in an art exposition in New York and have received positive feedback from artists that think this tool might be beneficial to them. If you’d like to run a simulation with your universe and characters, don’t hesitate to reach out. I will be happy to collaborate.
References:
[1] Park, J. S., O'Brien, J. C., Cai, C. J., Morris, M. R., Liang, P., & Bernstein, M. S. (2023). Generative Agents: Interactive Simulacra of Human Behavior. arXiv:2304.03442 [cs.HC]. https://doi.org/10.48550/arXiv.2304.03442
[2] Weiss, G. (1999). Multiagent systems: A modern approach to distributed artificial intelligence. MIT Press.
[3] https://developers.google.com/machine-learning/clustering/similarity/measuring-similarity
[4] Baumann, T. (2022). Cooperative Artificial Intelligence. arXiv:2202.09859 [cs.AI]. https://doi.org/10.48550/arXiv.2202.09859
[5] Nisan, N., Roughgarden, T., Tardos, É., & Vazirani, V. V. (Eds.). (2007). Algorithmic game theory. Cambridge University Press.
[6] https://github.com/davidrmiller/biosim4
[7] Lechner, M., Hasani, R., Amini, A., Henzinger, T. A., Rus, D., & Grosu, R. (2020). Neural circuit policies enabling auditable autonomy. Nature Machine Intelligence, Volume 2, 642–652. https://doi.org/10.1038/s42256-020-00237-31*
[8] Wilf, A., Lee, S. S., Liang, P. P., & Morency, L. P. (2023). Think Twice: Perspective-Taking Improves Large Language Models' Theory-of-Mind Capabilities. arXiv preprint arXiv:2311.10227.
[9] Sclar, M., Kumar, S., West, P., Suhr, A., Choi, Y., & Tsvetkov, Y. (2023). Minding Language Models'(Lack of) Theory of Mind: A Plug-and-Play Multi-Character Belief Tracker. arXiv preprint arXiv:2306.00924.
[10] Axelrod, R., & Hamilton, W. D. (1981). The evolution of cooperation. science, 211(4489), 1390-1396.